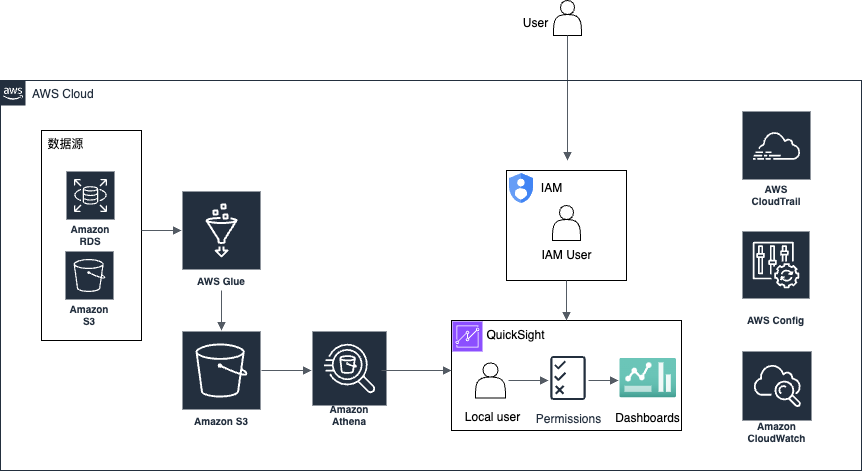
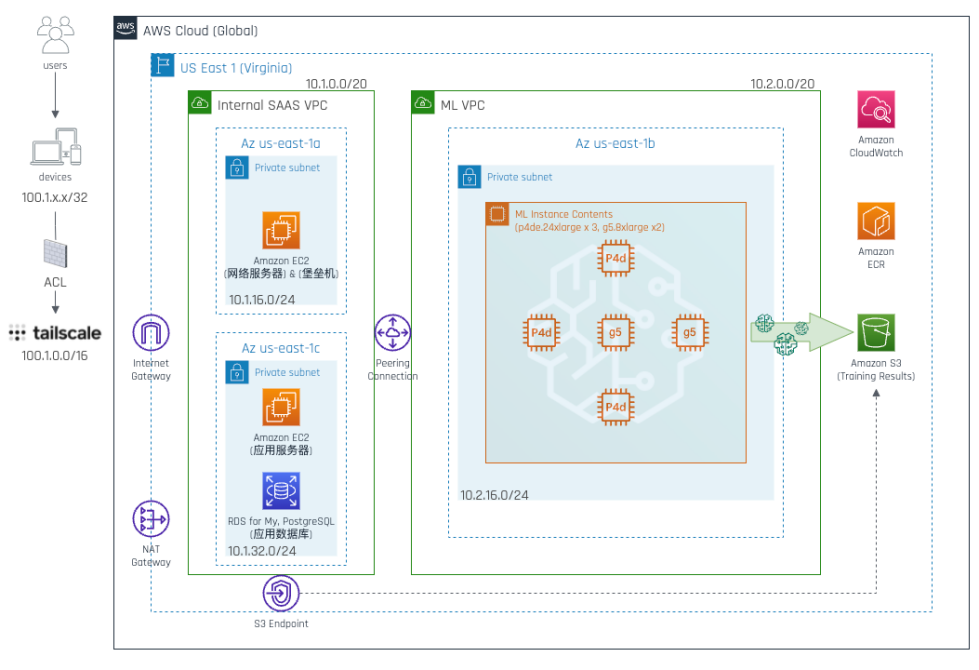
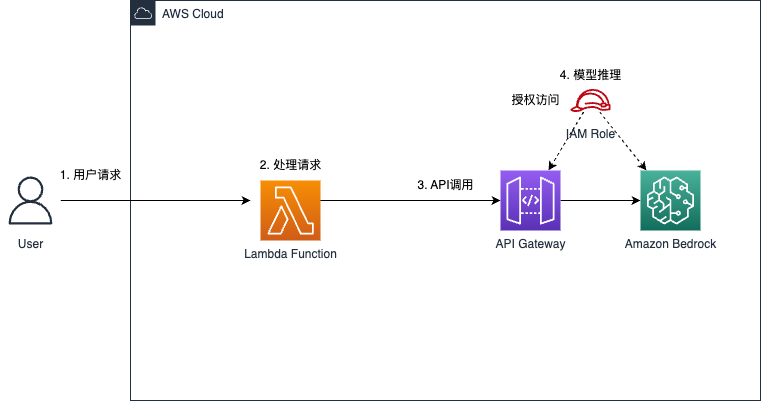
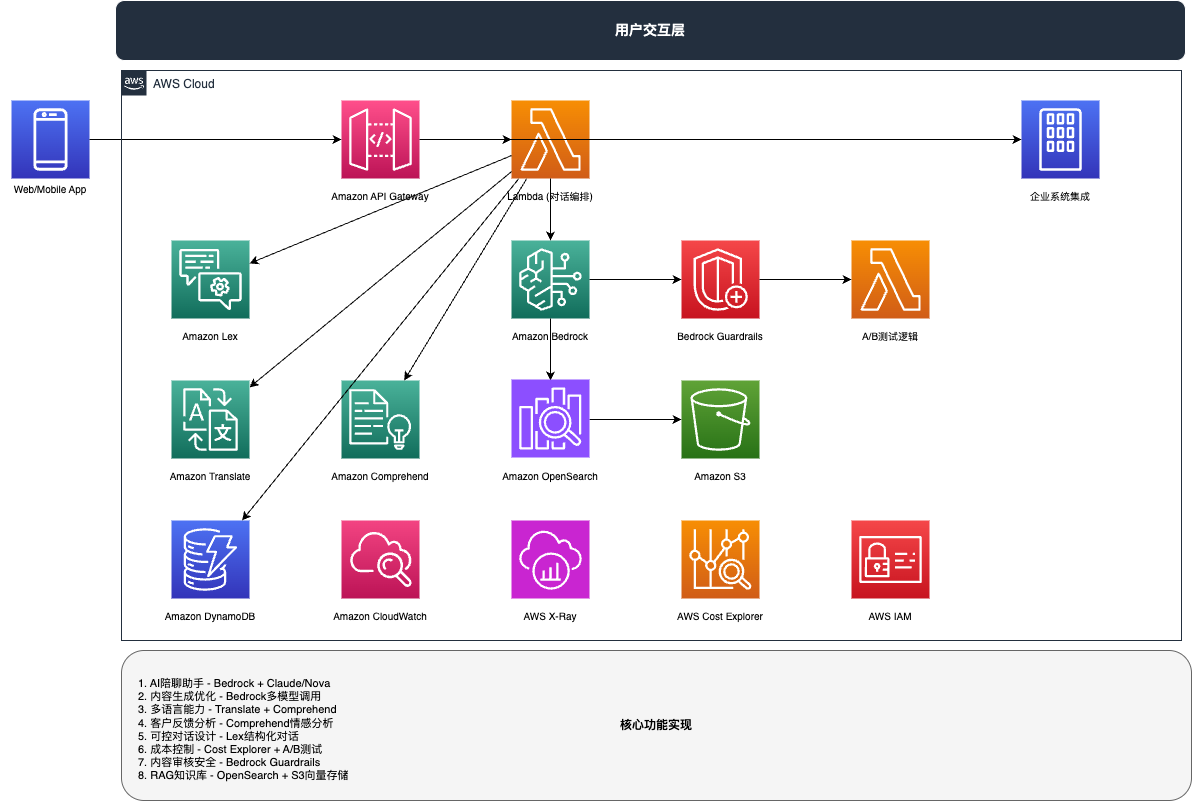
在构建大语言模型(LLM)应用时,开发者经常会面临两个问题:模型响应速度慢,以及推理成本高。Amazon Bedrock 针对这一痛点推出了「提示缓存(Prompt Caching)」功能,帮助开发者大幅提升 API 调用效率,同时显著节省成本。
什么是Amazon Bedrock提示缓存?
在许多生成式 AI 应用中,提示(Prompt)中会重复包含大量相同内容,比如系统指令、历史对话、上下文说明等。每次调用模型时,这些重复的提示部分都需要被重新处理,造成计算资源的浪费。
Amazon Bedrock 提示缓存的核心在于:将提示中重复的“前缀”部分缓存下来,后续调用时无需重复推理,从而减少延迟和成本。
与传统缓存不同,这不仅是文本缓存,而是对大型语言模型内部“神经状态”的缓存——包括注意力模式、标记关系等深层计算结果。Amazon Bedrock 会在指定检查点捕获这些状态,并安全存储在 AWS 内部的缓存层中,仅对本账户有效。
技术架构概览
Bedrock 的缓存系统构建在其推理执行环境上,与模型调用的执行路径高度集成,架构设计类似 AWS Lambda。缓存系统位于 API 和模型执行层之间,能够拦截请求并动态存储神经状态。
缓存分为两类操作:
- 写入缓存:首次遇到的提示前缀会触发缓存写入,稍微增加处理开销。
- 读取缓存:后续重复提示可直接从缓存读取神经状态,大幅降低处理负载。
该机制特别适合对提示内容重复率高的应用,如文档问答、对话机器人、代码生成助手等。
成本优化机制
提示缓存的最大优势之一是成本节省。以 Claude 3.5/3.7 Sonnet 为例(输入成本 0.003 美元/千 token):
类型成本/千 token描述正常输入$0.003标准推理调用缓存写入$0.00375成本增加约 25%缓存读取$0.0003成本降低高达 90%输出部分$0.015与缓存无关,价格相同
假设用户上传一个包含 3 万 token 的财报文档,并针对它提 8 个问题:
- 无缓存成本:每次问题都需重新处理文档,总计约 $0.72;
- 使用缓存:首个请求写入缓存,后续 7 次读取缓存,总成本约 $0.1755,节省约 75.6%。
如果您的系统每月需处理 10,000 份文档,使用提示缓存每月可节省超 $5,000 的成本。
适用场景与限制
提示缓存并非适用于所有场景。以下是建议启用缓存的典型用例:
- 长提示反复使用:如客服聊天历史、问答上下文、系统指令等;
- Agent 多轮推理:代理需反复引用环境设定或任务说明;
- 文档分析工具:针对相同文档反复提问;
- 代码助手:每次调用需重复加载相同项目上下文。
但在以下场景下,缓存收益不明显,甚至可能增加成本:
- 一次性提示:如每次处理的文档内容不同;
- 极短提示:低于触发缓存机制的最小阈值;
- 调用间隔过长:缓存有效期仅数分钟,超过时间即失效;
- 提示差异化大:前缀略有不同,可能导致缓存未命中。
因此,开发者应结合具体应用的调用模式,评估是否启用提示缓存,并通过 API 监控指标如 CacheReadInputTokens 和 CacheWriteInputTokens 量化使用效果。
与 Amazon Bedrock 其他功能集成
提示缓存可无缝集成到 Amazon Bedrock 的其他能力中:
- 与代理集成:支持构建更复杂的代理任务流程,提升响应速度;
- 长系统提示支持:无需为长指令反复支付高昂计算代价;
- 增强上下文稳定性:缓存提示前缀帮助构建更稳定的上下文链条。
整体来看,提示缓存特别适用于需要高频调用相同上下文的 LLM 应用场景。借助它,您可以大幅降低成本、缩短响应时间,构建更高效的 AI 服务。
结语
Amazon Bedrock 的提示缓存机制不仅是一项技术优化,更是企业级 AI 应用降本提效的重要工具。它帮助开发者在不牺牲准确性和上下文完整性的前提下,加快模型响应、节省成本,在真实业务中实现更具性价比的 LLM 推理体验。
如果您正在开发基于 Bedrock 的 AI 应用,不妨评估一下提示缓存带来的潜力收益。在大模型规模化落地的今天,优化每一个 token 的使用成本,就是赢得商业竞争的关键一步。